Dataset Exploration: IMDB Reviews
Project Objective:
The goal of this project is to classify IMDB movie reviews as either positive or negative based on the text content. The dataset contains 50,000 labeled reviews, evenly split between training and testing sets. The task uses natural language processing to extract features and machine learning to predict sentiments.
Dataset Analysis:
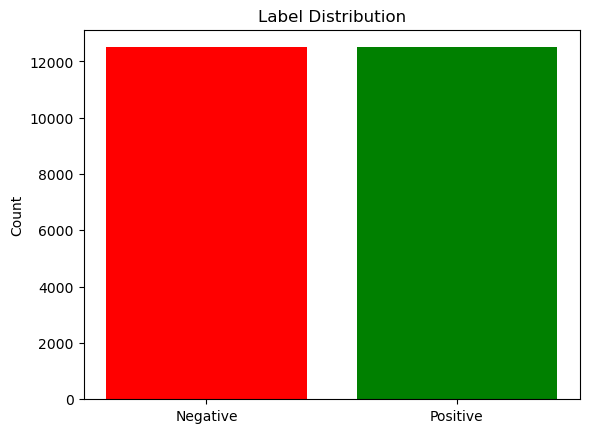
There are 25,000 data points in our training dataset. Each review is formatted with the id and actual rating, and within each text file is the word contents of the review. Each positive and negative review makes up half of the dataset (12,500 data points). The data is primarily skewed left, so it would make sense to use the median rather than the mean to describe the distribution of words per review.
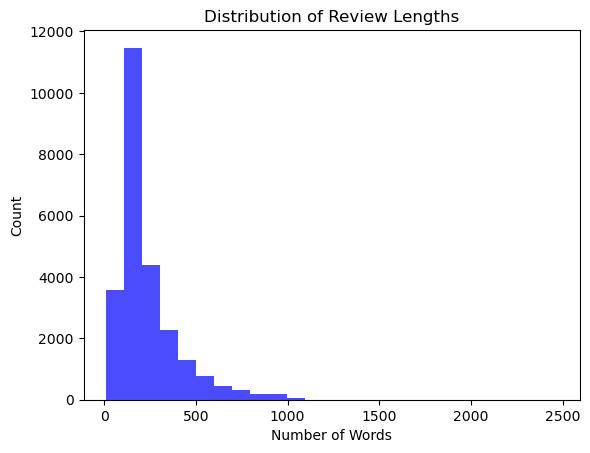
Reviews ranged from 100 to 300 words in length, with both positive and negative labels displaying similar length distributions. Common words in positive reviews include terms like "great," "amazing," and "loved," while negative reviews frequently use words such as "bad," "worst," and "boring." To prepare the data for analysis, we removed HTML tags, punctuation, and special characters. The text was then converted to lowercase to keep everything consistent. We also broke the reviews into individual words and cleaned up stopwords. In addition, to handle varying review lengths and styles, we used SBERT embeddings to convert the text into dense numerical vectors.
Design Choices / Models:
Vocabulary-Based MLP
The Vocabulary-Based MLP was trained using reviews transformed into integer sequences through TensorFlow's TextVectorization. The model used a single hidden layer with 64 neurons and ReLU activation. The training was performed with the Adam optimizer, a learning rate of 0.001, and binary cross-entropy loss.
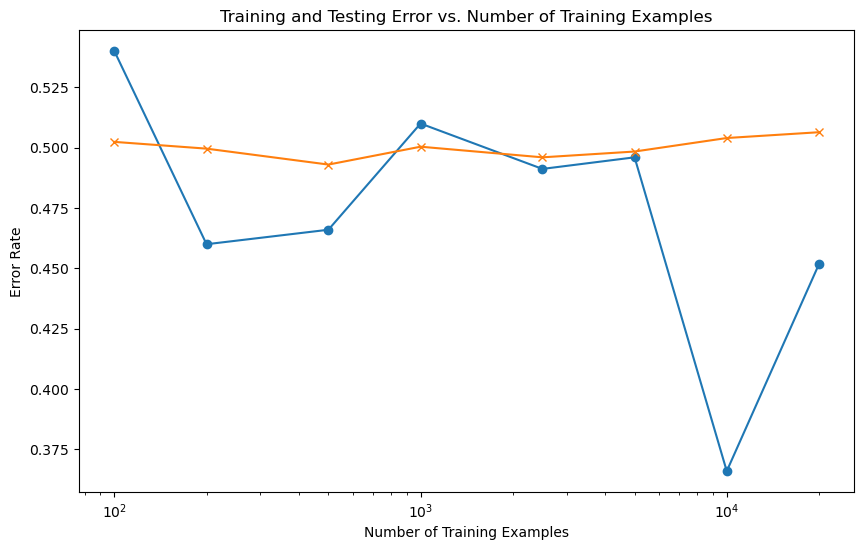
Despite these configurations, the model struggled to learn due to the equal treatment of padded elements, achieving only 50% test accuracy and a cross-validation score of 51%.
SBERT with MLP
Reviews were encoded into dense, fixed-length embeddings using SBERT (all-MiniLM-L6-v2). The MLP architecture consisted of three layers (256, 128, and 64 neurons) with ReLU activation functions. The Adam optimizer with a learning rate of 0.0001 and a batch size of 256 was used. Early stopping was applied to avoid overfitting. The training focused on optimizing the binary cross-entropy loss, and hyperparameters were refined through grid search.
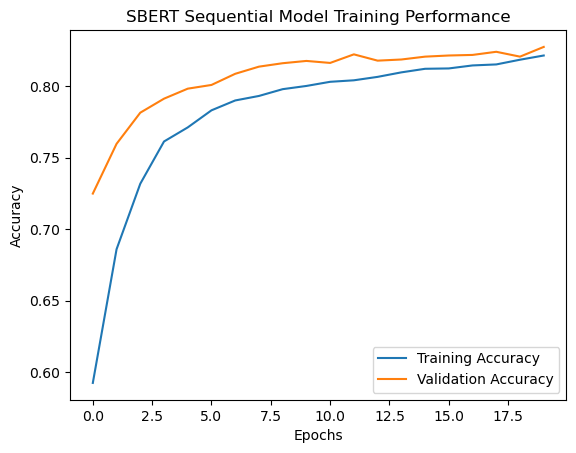
The model achieved a cross-validation accuracy of 49%, with improved test accuracy at 82.10%.
Keras Sequential Model
This model was designed with SBERT embeddings as input. The architecture includes three layers: 256 neurons, 128 neurons, and a final single neuron for binary classification. Dropout layers with rates of 0.3 and 0.2 were added for regularization. The Adam optimizer was employed with a learning rate of 0.001, and binary cross-entropy was used as the loss function. The training involved 20 epochs with a batch size of 16, and hyperparameters such as dropout rates and learning rates were tuned using grid search.
The model achieved a cross-validation accuracy of 81.65% and a test accuracy of 82.54%.
Random Forest
This ensemble combined SBERT embeddings with a Random Forest classifier. The model used 100 estimators and default hyperparameters for tree depth and splitting criteria. The training was performed on the entire dataset of SBERT embeddings, and the ensemble was evaluated using cross-validation and test accuracy metrics.
The model achieved 83.16% test accuracy, but it significantly overfitted the training data with an accuracy of 99%.
Gradient Boosting
Gradient Boosting was implemented using XGBoost, combined with SBERT embeddings and the optimized Keras Sequential model. The XGBoost parameters included 100 estimators, a learning rate of 0.1, and a maximum tree depth of 3.
The ensemble achieved 83.44% test accuracy and performed similarly to the Random Forest ensemble in terms of overfitting, with a training accuracy of 99%.
Challenges:
Initially, the MLPClassifier demonstrated poor performance with a cross-validation score of approximately 50%, highlighting the need for significant improvements in feature representation. Transitioning to SBERT embeddings greatly improved the model's ability to capture textual semantics. The Keras Sequential model, with dense layers and dropout regularization, was better suited for text data and effectively reduced overfitting. To address underfitting and overfitting, we tested various architectures, including RNNs, but they performed worse than SBERT-based models. We also considered introducing feature transformations, such as limiting the maximum number of words per review to reduce noise. Filtering out irrelevant words was another potential improvement not fully explored but identified as a priority for future work.
Performance Validation:
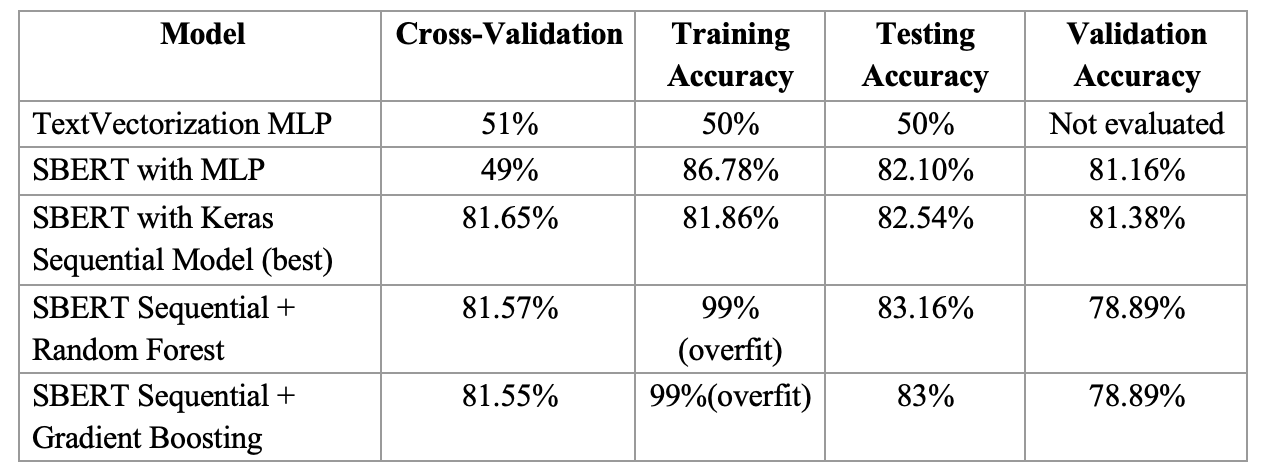
Comparing our CV and Training/Validation accuracy, we would deem the SBERT with Keras Sequential model most suitable based on overfitting/underfitting tradeoffs.
Conclusion:
In this project, we explored the analysis of IMDB movie reviews utilizing techniques like SBERT embeddings and neural network models. This dataset posed challenges related to text variability and overfitting, which were addressed through feature engineering and model design. SBERT embeddings significantly improved model performance by providing a semantic understanding of the reviews, while ensemble models achieved higher test accuracies at the cost of overfitting. In the future, exploring semi-supervised methods, like label propagation, could also improve results by leveraging both labeled and unlabeled data. Additionally, incorporating other techniques, such as limiting review lengths to the median number of words and filtering irrelevant terms, may enhance model performance. By observing how techniques work and how to make them work better, refining feature engineering and regularization methods can enhance model generalization.